在当今这个科技飞速发展的时代,汽车不仅是交通工具,更是科技进步的体现,当我们谈论一辆二手的路虎卫士时,不仅仅是在谈论一辆拥有独特设计风格和强大越野能力...
2024-09-21 3
谷歌也来卷「小」模型了,一出手就是王炸,胜过了比自己参数多得多的GPT-3.5、Mixtral竞品模型。
今年6月底,谷歌开源了9B、27B版Gemma2模型系列,并且自亮相以来,27B版本迅速成为了大模型竞技场LMSYSChatbotArena中排名最高的开放模型之一,在真实对话任务中比其两倍规模以上的模型表现还要好。
如今,仅仅过去了一个多月,谷歌在追求负责任AI的基础上,更加地考虑该系列模型的安全性和可访问性,并有了一系列新成果。
此次,谷歌开源最强端侧小模型:参数越级跑赢Gemma2不仅有了更轻量级「Gemma22B」版本,还构建一个安全内容分类器模型「ShieldGemma」和一个模型可解释性工具「GemmaScope」。具体如下:
Gemma22B具有内置安全改进功能,实现了性能与效率的强大平衡;
ShieldGemma基于Gemma2构建,用于过滤AI模型的输入和输出,确保用户安全;
GemmaScope提供对模型内部工作原理的无与伦比的洞察力。
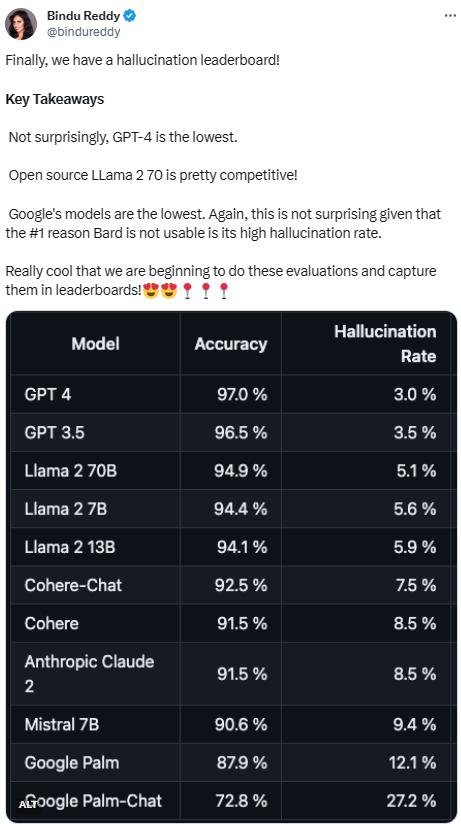
其中,Gemma22B无疑是「最耀眼的仔」,它在大模型竞技场LMSYSChatbotArena中的结果令人眼前一亮:仅凭20亿参数就跑出了1130分,这一数值要高于GPT-3.5-Turbo(0613)和Mixtral-8x7b。
这也意味着,Gemma22B将成为端侧模型的最佳选择。
苹果机器学习研究(MLR)团队研究科学家AwniHannun展示了Gemma22B跑在iPhone15pro上的情况,使用了4bit量化版本,结果显示速度是相当快。
此外,对于前段时间很多大模型都翻了车的「9.9和9.11谁大」的问题,Gemma22B也能轻松拿捏。
图源:https://x.com/tuturetom/status/1818823253634564134与此同时,从谷歌Gemma22B的强大性能也可以看到一种趋势,即「小」模型逐渐拥有了与更大尺寸模型匹敌的底气和效能优势。
这种趋势也引起了一些业内人士的关注,比如知名人工智能科学家、LeptonAI创始人贾扬清提出了一种观点:大语言模型(LLM)的模型大小是否正在走CNN的老路呢?
在ImageNet时代,我们看到参数大小快速增长,然后我们转向了更小、更高效的模型。这是在LLM时代之前,我们中的许多人可能已经忘记了。
大型模型的曙光:我们以AlexNet(2012)作为基线开始,然后经历了大约3年的模型大小增长。VGGNet(2014)在性能和尺寸方面都可称为强大的模型。
缩小模型:GoogLeNet(2015)将模型大小从GB级缩小到MB级,缩小了100倍,同时保持了良好的性能。类似工作如SqueezeNet(2015)和其他工作也遵循类似的趋势。
合理的平衡:后来的工作如ResNet(2015)、ResNeXT(2016)等,都保持了适中的模型大小。请注意,我们实际上很乐意使用更多的算力,但参数高效同样重要。
设备端学习?MobileNet(2017)是谷歌的一项特别有趣的工作,占用空间很小,但性能却非常出色。上周,我的一个朋友告诉我「哇,我们仍然在使用MobileNet,因为它在设备端具有出色的特征嵌入通用性」。是的,嵌入式嵌入是实实在在很好用。
最后,贾扬清发出灵魂一问,「LLM会遵循同样的趋势吗?」
图像出自Ghimire等人论文《ASurveyonEfficientConvolutionalNeuralNetworksandHardwareAcceleration》。Gemma22B越级超越GPT-3.5Turbo
Gemma2家族新增Gemma22B模型,备受大家期待。谷歌使用先进的TPUv5e硬件在庞大的2万亿个token上训练而成。
这个轻量级模型是从更大的模型中蒸馏而来,产生了非常好的结果。由于其占用空间小,特别适合设备应用程序,可能会对移动AI和边缘计算产生重大影响。
事实上,谷歌的Gemma22B模型在ChatbotArenaEloScore排名中胜过大型AI聊天机器人,展示了小型、更高效的语言模型的潜力。下图表显示了Gemma22B与GPT-3.5和Llama2等知名模型相比的卓越性能,挑战了「模型越大越好」的观念。
Gemma22B提供了:
性能卓越:在同等规模下提供同类最佳性能,超越同类其他开源模型;
部署灵活且经济高效:可在各种硬件上高效运行,从边缘设备和笔记本电脑到使用云部署如VertexAI和GoogleKubernetesEngine(GKE)。为了进一步提高速度,该模型使用了NVIDIATensorRT-LLM库进行优化,并可作为NVIDIANIM使用。此外,Gemma22B可与Keras、JAX、HuggingFace、NVIDIANeMo、Ollama、Gemma.cpp以及即将推出的MediaPipe无缝集成,以简化开发;
开源且易于访问:可用于研究和商业应用,由于它足够小,甚至可以在GoogleColab的T4GPU免费层上运行,使实验和开发比以往更加简单。
从今天开始,用户可以从Kaggle、HuggingFace、VertexAIModelGarden下载模型权重。用户还可以在GoogleAIStudio中试用其功能。
下载权重地址:https://huggingface.co/collections/google/gemma-2-2b-release-66a20f3796a2ff2a7c76f98f
Gemma22B的出现挑战了人工智能开发领域的主流观点,即模型越大,性能自然就越好。Gemma22B的成功表明,复杂的训练技术、高效的架构和高质量的数据集可以弥补原始参数数量的不足。这一突破可能对该领域产生深远的影响,有可能将焦点从争夺越来越大的模型转移到改进更小、更高效的模型。
Gemma22B的开发也凸显了模型压缩和蒸馏技术日益增长的重要性。通过有效地将较大模型中的知识提炼成较小的模型,研究人员可以在不牺牲性能的情况下创建更易于访问的AI工具。这种方法不仅降低了计算要求,还解决了训练和运行大型AI模型对环境影响的担忧。
ShieldGemma:最先进的安全分类器
技术报告:https://storage.googleapis.com/deepmind-media/gemma/shieldgemma-report.pdfShieldGemma是一套先进的安全分类器,旨在检测和缓解AI模型输入和输出中的有害内容,帮助开发者负责任地部署模型。
ShieldGemma专门针对四个关键危害领域进行设计:
仇恨言论
骚扰
色情内容
危险内容
这些开放分类器是对负责任AI工具包(ResponsibleAIToolkit)中现有安全分类器套件的补充。
借助ShieldGemma,用户可以创建更加安全、更好的AI应用
SOTA性能:作为安全分类器,ShieldGemma已经达到行业领先水平;
规模不同:ShieldGemma提供各种型号以满足不同的需求。2B模型非常适合在线分类任务,而9B和27B版本则为不太关心延迟的离线应用程序提供了更高的性能。
如下表所示,ShieldGemma(SG)模型(2B、9B和27B)的表现均优于所有基线模型,包括GPT-4。
GemmaScope:让模型更加透明
GemmaScope旨在帮助AI研究界探索如何构建更易于理解、更可靠的AI系统。其为研究人员和开发人员提供了前所未有的透明度,让他们能够了解Gemma2模型的决策过程。GemmaScope就像一台强大的显微镜,它使用稀疏自编码器(SAE)放大模型的内部工作原理,使其更易于解释。
GemmaScope技术报告:https://storage.googleapis.com/gemma-scope/gemma-scope-report.pdfSAE可以帮助用户解析Gemma2处理的那些复杂信息,将其扩展为更易于分析和理解的形式,因而研究人员可以获得有关Gemma2如何识别模式、处理信息并最终做出预测的宝贵见解。
以下是GemmaScope具有开创性的原因:
开放的SAE:超过400个免费SAE,涵盖Gemma22B和9B的所有层;
交互式演示:无需在Neuronpedia上编写代码即可探索SAE功能并分析模型行为;
易于使用的存储库:提供了SAE和Gemma2交互的代码和示例。
参考链接:
https://developers.googleblog.com/en/smaller-safer-more-transparent-advancing-responsible-ai-with-gemma/
相关文章

在当今这个科技飞速发展的时代,汽车不仅是交通工具,更是科技进步的体现,当我们谈论一辆二手的路虎卫士时,不仅仅是在谈论一辆拥有独特设计风格和强大越野能力...
2024-09-21 3

比亚迪F0作为比亚迪汽车的一款经典微型车,自推出以来便以其独特的市场定位和出色的产品性能赢得了广大消费者的青睐,这款车型不仅在设计上追求时尚与实用的完...
2024-09-21 1

在汽车市场中,沃尔沃一直以制造高性能、高安全性以及极具设计感的车型而著称,V50作为一款紧凑型旅行车,在市场上获得了极高的评价,它不仅继承了沃尔沃一贯...
2024-09-21 3

在北京现代汽车4S店的智能化升级过程中,通过引入先进的科技手段,不仅可以提升顾客体验,还能增强售后服务效率和质量,从而在激烈的市场竞争中占据优势,以下...
2024-09-21 3

```html苹果发布会PPT大纲苹果发布会PPT大纲介绍苹果发布会的背景和重要性。概述发布会的时间、地点及主题。3.1iPhone系列介绍新款iPh...
2024-09-21 270 苹果发布会2024春季发布会时间 2023苹果发布会 苹果发布会在哪里可以看直播 2024年苹果发布会时间

在当今这个快速发展的时代,汽车技术的进步日新月异,每一款新车的问世都承载着人们对未来出行方式的美好憧憬,四川丰田柯斯达(Toyota Coaster)...
2024-09-21 4

```html华为手机:你的最佳选择!最近很多小伙伴问我,华为手机到底好不好?今天就来给大家分享一下我的使用体验!华为手机搭载的麒麟芯片,性能杠杠的!...
2024-09-21 892 华为手机官网 华为手机锁屏密码忘了怎么解开 华为手机怎么找wifi二维码 华为手机返回键怎么调出来
