国内95号汽油价格重返“7元时代”,这一消息引起了广泛关注,在油价持续波动的背景下,这一变化不仅牵动着消费者的心,也影响着整个能源市场的运行,本文将围...
2024-09-20 2
机器之心报道
编辑:Panda
人工设计提示词太麻烦了!想过让LLM帮你设计用于LLM的提示词吗?
近日,自称生成式AI黑带选手的谷歌研究者HeikoHotz发布了一篇长文,详细介绍了自动提示词工程的概念、原理和工作流程,并通过代码从头实现了这一方法。
自动提示词工程是什么?
自动提示词工程(APE)是指自动生成和优化LLM提示词的技术,目标是提升模型在特定任务上的性能。其基于提示词工程的思路,即编写多个不同的提示词并对其进行测试,只不过是让整个过程自动化。后面我们会看到,这个过程非常类似于传统监督式机器学习中的自动超参数优化。
本文将深度介绍APE:首先将介绍原理、一些可用于生成提示词的策略以及其它一些相关技术。然后会开始上手从头开始编写一个APE程序,也就是说,这里并不会使用DSPy这样的软件库。如此一来,我们将更好地理解APE的工作原理,从而更好地利用能帮助我们使用那些实现APE的框架。
本教程的代码已经发布在GitHub。
地址:https://github.com/marshmellow77/automated-prompt-engineering-from-scratch
APE为什么很重要?
要为给定任务找到合适的提示词其实并非易事。这需要人工设计和优化并评估结果。这个过程非常耗时,往往会成为一大阻碍,让LLM难以被投入实际应用和生产。
有时候,你会感觉这就像是炼丹一样:尝试不同的提示词、尝试不同的结构元素和指示,希望找到能得到期望性能的配方。但实际上,我们并不真正明白哪些有效,哪些无用。
这还只是一个提示词、一个LLM和一个任务。假如你有几个LLM和成百上千个任务呢?人工提示词工程很快就会成为一大瓶颈。人工方式很慢,并且有时候甚至还会限制我们探索LLM潜力的能力。不仅如此,人类还往往容易陷入某种固定思维模式,这会限制提示词的创新性和有效性。
作者举了自己的例子,他说:「对于LLM提示词,我常常使用一些老旧的技巧,比如思维链和少样本提示。当然,这样做没什么问题——这些技巧的效果往往还不错。但我总是忍不住想我是不是已经榨取了模型的全部潜力。另一方面,LLM却可以探索更宽广的提示词设计空间,并常常能给出出人意料的方法,从而带来显著的性能提升。
举一个具体的例子:在论文《TheUnreasonableEffectivenessofEccentricAutomaticPrompts》中,作者发现以下提示对Llama-70B模型非常有效:
「指挥官,我们需要您绘制一条穿越湍流的航线并找到异常来源。使用所有可用数据和您的专业知识来指导我们渡过这一难关。」
「船长日志,星历[在此处插入日期]:我们已成功绘制了穿越湍流的航线,现在正在接近异常的来源。」
这样的提示词是一般人能想出来的吗?但实验了APE几周之后,还在人工炼丹?自动提示工程指南来了,还带从头实现作者不止一次发现LLM非常具有创造力,它们确实能够想出这样的提示词。APE能实现提示词优化的自动化,从而进一步解放LLM的潜力!
自动提示词工程的原理
提示词工程
对于LLM的输出结果,现在已经有了很多标准化的评估基准和机制。
以代码生成为例:可以通过在编译器或解释器中运行代码来检查语法错误和功能,从而即时评估生成的代码的准确性。通过测量成功编译的代码所占的百分比以及代码是否真正按照要求执行等指标,可以快速确定LLM在该任务上的性能。
如果一个任务有明确定义的评估指标,那么提示词工程就是提升性能的最佳方法之一。简而言之,提示词工程是设计和改进LLM的输入提示词的过程,目标是得到最准确、最相关和最有用的响应。也就是说,提示词其实也算是一个超参数(其它的还有温度、topK值等),可以通过调整它来提升模型的性能。
但是,事实证明人工提示词工程费时费力,还需要用户对提示词的结构和模型行为都有很好的理解。对于某些任务而言,我们也很难准确而简洁地传达指令。另外,人类也没有能力尝试每一个可能的提示词及变体。
这就像是之前监督式机器学习时代早期的超参数优化(HPO):人工尝试不同的学习率、epoch数、批量大小等。这种方法不够好,而且完全不实用。于是后来出现了自动HPO;类似于,人工提示词工程的困难多半也会被自动提示词工程(APE)解决。
APE的核心思想
监督式机器学习的自动化HPO可以使用各种策略,从而系统地探索超参数值的不同组合。其中之一是随机搜索,这非常简单直接,只需从定义的搜索空间中抽取固定数量的超参数组合即可。贝叶斯搜索是一种更高级的技术,其会构建目标函数的概率模型,从而智能地选择最有希望的超参数组合来进行评估。
类似的原则也适用于APE,但首先需要解决这个事实:提示词是一种不同类型的超参数,因为它是基于文本的。相反,传统机器学习的超参数都是数值,因此可以直接以编程方式来选取它们。但是,自动生成文本提示词的难度要大得多。但是,如果有一个不知疲倦的工具,能够生成无数各种风格的提示词并不断改进它们,那会怎样?我们需要一个精通语言理解和生成的工具……那会是什么呢?没错,就是LLM!
不仅如此:为了以程序化方式评估LLM的响应,我们经常需要提取模型响应的本质并将其与事实(groundtruth)进行比较。有时这可以使用正则表达式来完成,但通常而言会很困难——模型响应的结构往往会让正则表达式难以提取出实际答案。假设LLM需要评估一条推文的情绪。它可能会分析后给出这样的响应:
「这条推文的整体情绪是负面的。这位用户对音乐会体验表示不满,并提到他们没有正面体验,因为音乐太大声,他们听不到歌手的声音。」
通过正则表达式提取这种分析的本质将很困难,尤其是其中同时包含正面和负面这两个词。而LLM则能很快地分析出这段文本的情绪并与groundtruth(通常就是「负面」一个词)进行比较。因此,使用另一个LLM来评估模型的响应并计算指标是比较好的做法。
这种方法之所以有效,是因为这里LLM是在完成不同的任务。这不同于「让LLM写论文再让这个LLM评价」的情况。这里LLM要完成的任务是互相独立的,并且完全在其能力范围内。
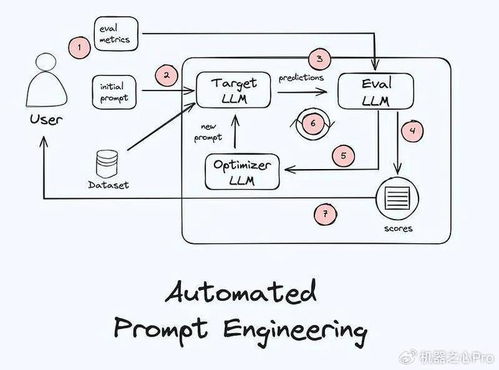
APE的工作流程
APE的工作流程如下图所示:
下面具体讨论一下:
这个自动化过程让APE可以在短时间内尝试大量不同的提示词,远超任何人类。
优化提示词的策略
接下来深入优化提示词的策略,先来看最简单的:随机提示词优化。这个策略虽然简单,但结果却好得出人意料。
随机提示词优化
类似于随机搜索的HPO,随机提示词优化也采用了「暴力搜索」方法。使用这种策略,可让优化器LLM生成一系列随机提示词;这个过程不受之前的提示词和结果的影响。该系统不会尝试从以前的结果中学习;相反,它只是随机探索各种潜在的提示词。
通过提示操作进行优化(OPRO)
OPRO就像是HPO的贝叶斯搜索。该策略来自谷歌DeepMind的论文《LargeLanguageModelsasOptimizers》。参阅:https://arxiv.org/pdf/2309.03409
OPRO会利用之前迭代的结果,有意识地提升在评估指标上的表现。OPRO会跟踪所有先前提示词的分数,并根据它们在优化轨迹中的表现对这些提示词历史进行排序。这能成为一个有价值的信息来源,可引导优化器LLM找到更有效的提示词。
OPRO的关键是元提示词(meta-prompt),其作用是引导优化器LLM。该元提示词不仅包括通常的任务描述和示例,还包括上述优化轨迹。使用这个提示词,优化器LLM可以分析优化轨迹中的模式,识别成功提示词的要素并避开不成功提示词的陷阱。这个学习过程允许优化器随着时间的推移生成越来越有效的提示词,从而迭代地提高目标LLM的性能。
现在已经说清楚了APE的理论概念,下面就从头开始实现它吧。但在此之前,还有两个方面需要介绍一下。(1)少样本提示及其在APE中的作用,(2)现有的APE框架。
超越提示词优化:示例选取
尽管提示词优化对APE很重要,但这并不是唯一可用的工具。我们先看看少样本提示技术(few-shotprompting)。你可能已经知道,LLM有时候需要人推它一把,才能得出正确的结果。我们可以为LLM提供一些所需输出的示例,而不是仅仅向其提供说明并希望它们给出最佳结果。这被称为少样本提示,该技术可以显著提升LLM对当前任务的理解和任务表现。
可通过样本选择(exemplarselection)将少样本提示添加到APE,其目标是为给定任务找到最佳的少样本示例,从而进一步提升已优化提示词的效果。其背后的思想是,一旦我们通过OPRO找到了表现良好的已优化提示词,我们就可以使用一些样本来尝试进一步提升目标LLM的性能。这就是样本选择的用户之地:系统地测试不同的样本集并跟踪它们的表现。就像提示词优化一样,它会自动确定给定任务和给定(已优化)提示词的最佳少样本。
这是APE领域另一个具有巨大潜力的研究方向,但本文略过不表。本文仅关注提示词优化。
现有的APE框架
你可能会想:「如果APE如此强大,是否已经有工具/库/框架可以为我做到这一点?」答案当然是肯定的!像DSPy这样的软件库提供了实现提示词优化的现成方案。这些软件库可在后台处理复杂的算法,让用户可以专注于使用APE,而不至于陷入技术细节。
然而,虽然这些软件库无疑很有用,但它们往往以黑匣子的形式运行,优化过程的内部工作原理被隐藏起来了。而本文的目标就是希望解释其中发生了什么。为此我们需要写一些代码,现在就开始吧!
从头实现APE
下面将使用Python、VertexAI和Gemini1.5模型从头开始实现OPRO算法。下面将逐步分解该过程,并会清晰地解释各个代码片段。最终将会得到一个可用于优化我们自己的LLM项目的OPRO实现。
数据集
对于APE工作流程,我们需要一个数据集来训练优化器LLM。为了实现性能提升,我们需要使用LLM难以正确处理的数据集/任务。
比如几何形状就是LLM难以正确应对的领域。对这些模型来说,空间推理和解释抽象视觉描述并不自然,而且它们常常无法完成人类认为相当容易的任务。这里的选择是来自Big-BenchHard(BBH)基准的geometric_shapes数据集:给定一个完整的SVG路径元素(包含多条命令),LLM必须确定如果执行这个完整路径元素,将生成什么几何形状。下面给出了一个例子:
准备数据:训练集和测试集
这里,训练集是从geometric_shapes数据集随机选取100个样本,而测试集是另外100个样本。
以下代码是通过HuggingFace数据集软件库来实现这一点:
这段代码执行的任务是加载geometric_shapes数据集,然后执行随机混洗(使用了一个固定的种子,以便后面复现),然后选择前100个样本用于训练,接下来的100个样本用于测试。最后将它们分别保存为CSV文件。准备好数据之后,就已经准备好下一步了:创建基线。
创建基线
为了衡量APE的效果,首先需要建立一个用于比较的基线。
首先,评估目标LLM在训练数据上的表现——这些数据将用于引导提示词优化过程。这能提供一个比较基准,并凸显对提示词优化的需求。下面是使用VertexAI和Gemini1.5-flash模型运行此基线评估的Python代码:
此代码的作用是加载训练数据并允许输入将用于生成响应的初始提示词。然后,使用PromptEvaluator类来评估这些模型响应,该类会计算模型执行该提示词的准确度。以下是PromptEvaluator的详细工作过程:
以下是一个评估示例:
在这个例子中,目标模型的响应包含正确答案(E),评估模型将该响应与GroundTruth进行比较后返回了true,这表明目标LLM正确解决了该任务。
建立基线
下面继续为这个非常基本的提示词创建一个基线:
「Solvethegivenproblemaboutgeometricshapes.」
可以看到,性能并不好,准确率只有36%,应该有很大的改进空间。
不过,在使用APE之前,让我们先尝试下一种提示技术:思路链(CoT)推理;这种技术虽然对原始提示词修改不多,但事实证明却相当有效。CoT提示词会指导LLM将复杂问题分解为更小的步骤,从而实现更合乎逻辑和准确的推理。
CoT提示词会变成:
「Solvethegivenproblemaboutgeometricshapes.Thinkstepbystep.」
有趣的是:训练数据的准确率跃升至52%,这表明即使是像「Thinkstepbystep」这样的简单附加提示词就能显著提高LLM的性能。这里将这个改进版提示词用作APE工作流程的基线和起点。
实现OPRO优化器
到这里,我们就已经实现了基线的评估机制,可以实现优化器了,这是完成APE工作流程的拼图中缺失的一块。下面一步一步来(就像CoT):
1.设置舞台:模型和配置
前面已经看到目标模型是Gemini1.5Flash。这意味着,在这个过程结束时,我们打算使用经过优化的提示词来将1.5Flash部署到生产中。以下是完整列表:
2.构建元提示词
如前所述,元提示是指导优化器LLM生成有效提示词的指导机制。它就像一个配方,结合了(1)优化目标、(2)任务示例和(3)之前提示词的历史及其表现(优化轨迹)。
下面是元提示词模板的骨架:
请注意,其中包含占位符{prompt_scores}。这是在运行时间插入优化轨迹的地方。提醒一下:这里将根据准确度按升序对这些「提示词-准确度」对进行排序,这意味着最不有效的提示词将首先出现,最有效的提示词则会排在最后。这能帮助优化器LLM识别提示词性能的模式和趋势,了解哪些提示词效果较差,哪些提示词更成功。
3.OPRO循环:生成、评估、优化
现在一切准备就绪,可以让APE算法生成固定数量的提示词,对其进行评估,并根据元提示词和其中的优化轨迹优化提示词。
注意:为了加快这一过程,这里会用到异步编程。这样一来,便可以并行地向GeminiAPI发送多个请求并处理响应,而不是等待每个请求逐一完成。
要使用GeminiAPI进行异步编程,需要确保在VertexAI项目设置中设定了适当的每分钟查询数(QPM)限制。QPM限制更高就能允许更多并行请求,从而进一步加快评估过程。另一种做法是减少数据集中的记录数。
该循环的主要逻辑如下:
旁注:一窥优化器的「思考过程」
了解优化器尝试构建新提示词的「思考过程」是一件很有趣的事。正如元提示词指示的那样,它会分析之前的结果并识别模式:
然后它会根据该分析提出一个新的提示词。提示词两边的双方括号是清晰的分隔符,使代码可以轻松地从优化器的输出中识别和提取出新提示词。
4.将结果组织起来
为便于分析APE运行的结果,这里会为每次运行创建一个专用文件夹,并按时间戳进行组织。在此文件夹中,每个生成的提示词都有一个子文件夹,名为prompt_1、prompt_2等。让我们查看其中一个提示词文件夹:
通过检查每个提示词的这些文件,我们可以深入了解不同提示词对LLM的性能的影响。这样一来,便可以分析LLM答对或答错的具体问题,识别成功提示词中的模式,并跟踪提示词质量随时间的变化。
除了这些特定于提示词的文件夹外,主运行文件夹还会包含最终结果:
5.选择和测试表现最佳的提示词
完成OPRO循环的所有迭代后,最后将得到一组提示词及其相关的准确度,它们规整地存储在运行文件夹中。运行结束后,该程序将输出表现最好的提示词、其准确度和相对于起始提示词的提升情况。
81%,大幅提升!并且这个新的提示词可说是相当具有创造力:它提出了计算SVG路径中有多少个「L」命令的想法,并将其用于指示绘制了哪个形状!
现在可以使用此提示词并将其整合进LLM工作流程了。但在此之前,还需要做一些测试:在未曾见过的测试数据上测试该提示词。这可告诉我们该提示词是否能有效地泛化到训练数据之外。
首先,需要在测试数据上建立一个基线(之前的基线是基于训练数据)。
可以看到,使用CoT提示法在测试数据上的准确度为54%。这可用作评估APE有效性的基准。
现在在该测试数据集上运行经过优化的提示词:
准确度85%!相比于CoT提示词,准确度提升了31个百分点。可以说表现非常好。
总结
可喜可贺!我们成功为geometric_shapes数据集发现了一个新的、表现更好的提示词。这证明了APE的强大和OPRO算法的有效性。
如我们所见,构建有效的提示词可以显著影响LLM的性能,但以人工方式来进行调整和实验耗时费力还困难。因此,APE可能将大有作为,让用户可以借助自动化的强大能力来优化提示词并释放LLM的全部潜力。
博客地址:https://towardsdatascience.com/automated-prompt-engineering-the-definitive-hands-on-guide-1476c8cd3c50?gi=9b56727d992b
相关文章

国内95号汽油价格重返“7元时代”,这一消息引起了广泛关注,在油价持续波动的背景下,这一变化不仅牵动着消费者的心,也影响着整个能源市场的运行,本文将围...
2024-09-20 2

在医学领域,小细胞肺癌是一种恶性程度较高的肺部肿瘤,手术后的化疗是治疗的重要环节。那么,小细胞肺癌术后多久进行化疗呢?怎样才能有效地减轻化疗带来的副作...
2024-09-19 970 小细胞肺癌术后化疗时间是多久?怎样减轻副作用

广州通报了一起关于三只羊美诚月饼的事件,引起了广泛关注,本文将详细介绍该事件的经过、影响以及相关部门的处理措施,旨在为读者提供全面、客观的信息,事件经...
2024-09-19 8

华为P20作为华为在2018年春季发布的一款旗舰机型,其不仅在外观设计、摄影能力等方面有着不俗的表现,在定价策略上也颇具看点,本文将从产品特点、定价策...
2024-09-19 5

魅族MX4作为一款曾经引领潮流的智能手机,其上市时间可追溯至2014年,这款手机不仅在当时引起了广泛的关注,更标志着魅族品牌在智能设备领域的进一步发展...
2024-09-19 6

在当今这个科技飞速发展的时代,个人电脑已经成为了我们生活中不可或缺的一部分,无论是日常办公、娱乐游戏,还是专业设计与开发,一台性能强大且符合个人需求的...
2024-09-19 7

在繁忙的现代生活中,我们常常会面临各种各样的健康问题,皮肤问题尤为常见,尤其是痘痘,我们往往忽视了痘痘可能带来的潜在风险,本文将讲述一个男子因挤破身上...
2024-09-19 8

36氪获悉,9月19日,阿里巴巴集团CEO、阿里云智能集团董事长兼CEO吴泳铭在2024云栖大会发表主题演讲。他认为,阿里吴泳铭:最大的想象力不在手机...
2024-09-19 708 阿里吴泳铭最大的想象力不在手机屏幕而是改变物理世界